つづき
9.特徴量の削減その2
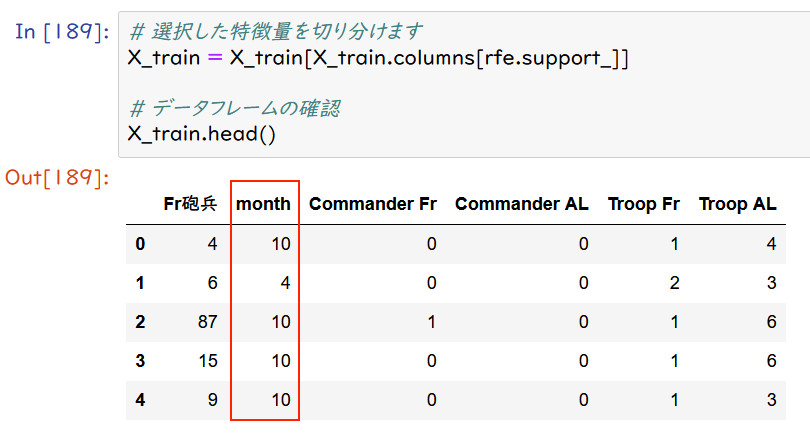
戦いの年月日、戦場の位置(緯度、経度)を追加した中で、特徴量を6ケに
削減した場合に、どの特徴量が残るか試してみた(実際の予測には使わない)。
(1)残った特徴量
年月日と位置の追加前に比べて、AL砲兵(連合軍砲兵中隊数)の代わりに月が入った。
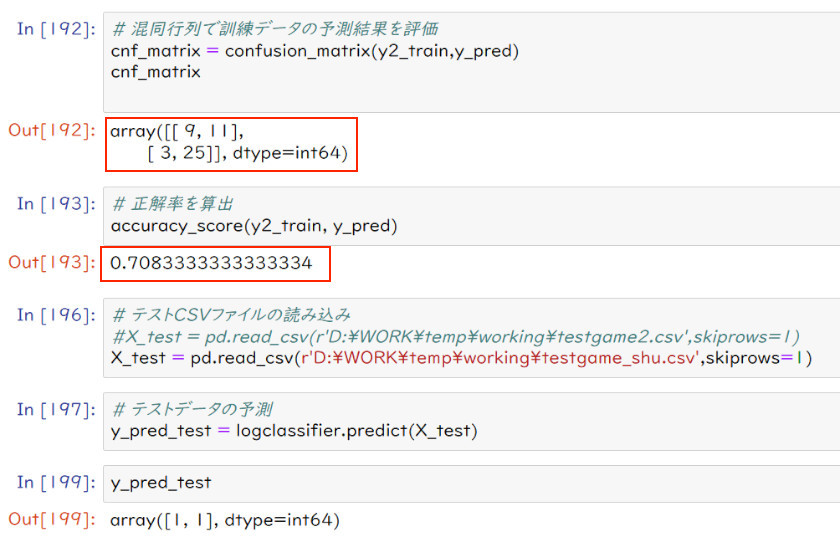
(2)正解率の変化
年月日と位置の追加前に比べて、66.67→70.83%に向上した。
10.入力データの標準化
特徴量によっては、データの範囲が違う。codExaでは、機械学習の計算量を小さくする為に、
正規化(その中の1つの手法に標準化:平均を0,標準偏差を1とする変換)を行っていた。
そこで、今回も標準化を行い、その効果を見てみる。データ量が小さいので、計算量(計算時間)
よりも予想精度に影響があるかどうかを目的に調べる。
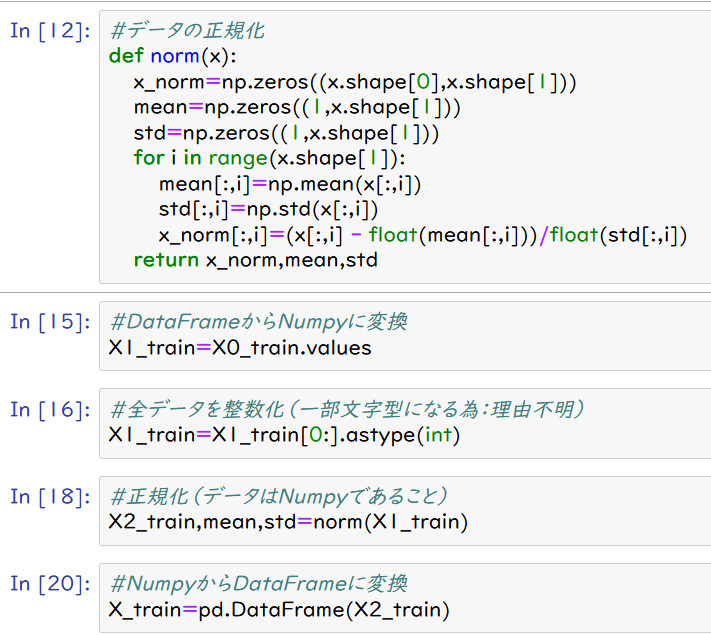
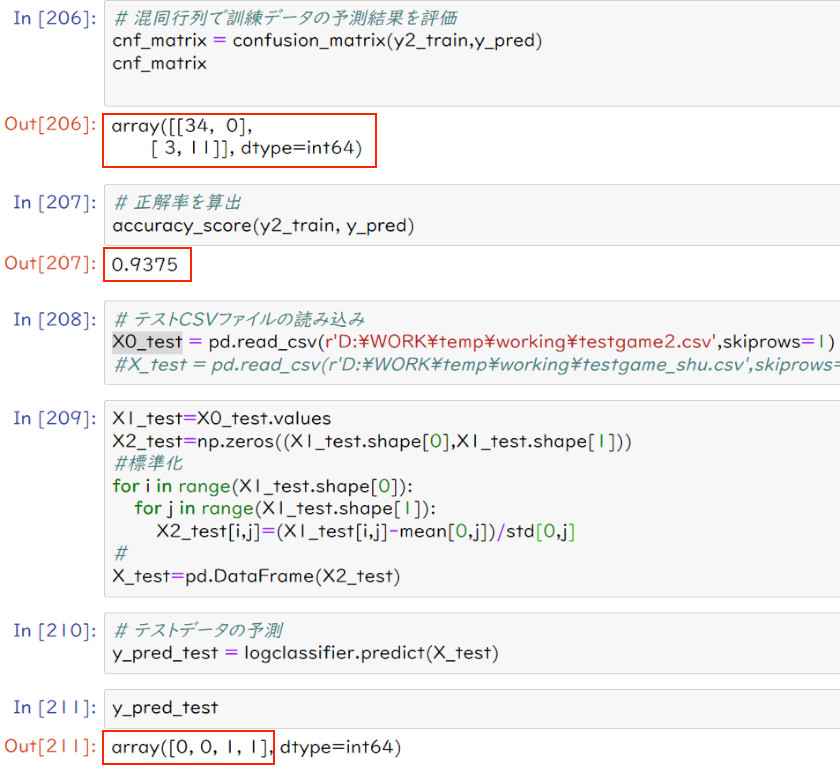
(1)コーディング例
下図のセル12から20のように変換を行った。なお、X0_trainが標準化前のX_trainと
同じ内容になっている。また、標準化計算を行う為には、データがNumpy配列になっている
必要があるので、一度変換してから標準化し、その結果をDataFrame型に戻している。
(2)結果
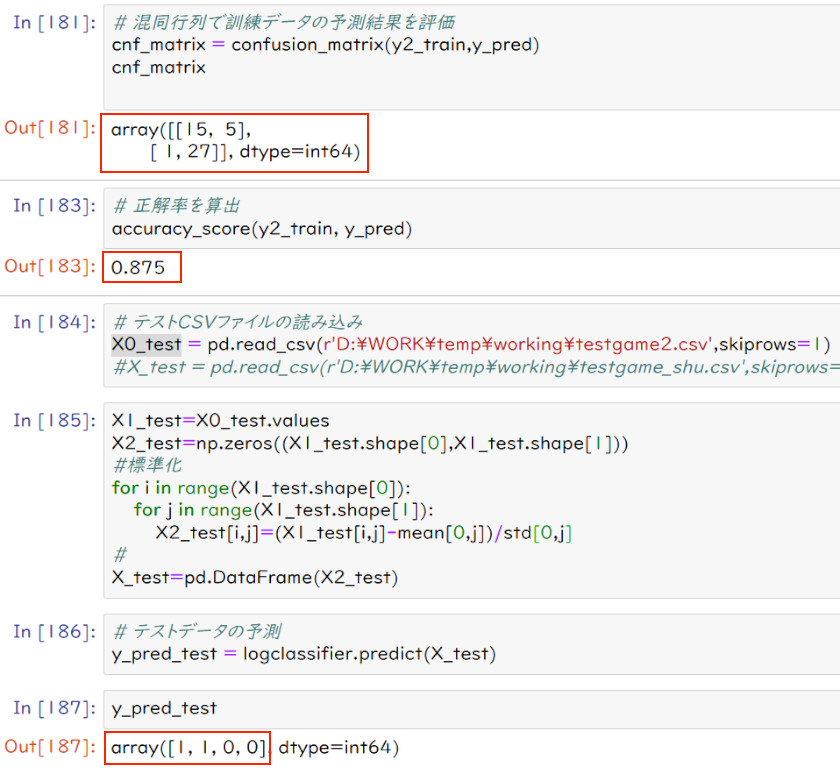
(A)フランス軍の勝ち予想
混同配列、正解率とも標準化前と同じである。しかし、予想結果(ノーヴィ、シェンカーバン、キャトルブラ、
モンサンジャン)の中で、ノーヴィが”勝ち以外”から”勝ち”と悪くなっている。
(B)フランス軍の負け予想
混同配列、正解率とも標準化前と同じである。しかし、予想結果(ノーヴィ、シェンカーバン、キャトルブラ、
モンサンジャン)の中で、2つが変わっている。
ノーヴィ : ”負け”から”負け以外”と悪くなった
キャトルブラ : ”負け以外”から”負け”と良くなった
次回へつづく
<個人的な感想>
特徴量の優先度で、”月”が連合軍砲兵中隊数よりも高いのは意外である。季節が勝敗に影響するらしい。
また、計算量を少なくする為の標準化が、予想精度を変えているのも、意外である。
・単純な変化から判断すると、標準化は精度を下げているように見える。
勝ちの予想 : ノーヴィの予想が悪くなる。
負けの予想 : ノーヴィの予想が悪く、キャトルブラの予想が良くなる。
・正解率などの性能評価から判断すると、標準化は精度に影響がないように見える。
上記2つの見方から考えると、標準化と予想精度の関係は判断が難しい。
codExaでは、一般的に標準化すると精度は上がると言っている。データ量がもっと
大きくなると、そうなのかもしれない。当面は、標準化を行って予想する事にして、様子をみる。