つづき
(8)劣化しない画像の場合
撮影したものではなく、オリジナルのデジタル画像を基にした場合のOCR機能を試してみた。
具体的には、Marshal Enterpreisesのシェンカーバンの戦いのユニット画像
(pdf形式)から下図のデータを取り込み、JPG形式に変換したものを使った。
原寸大(100%表示)

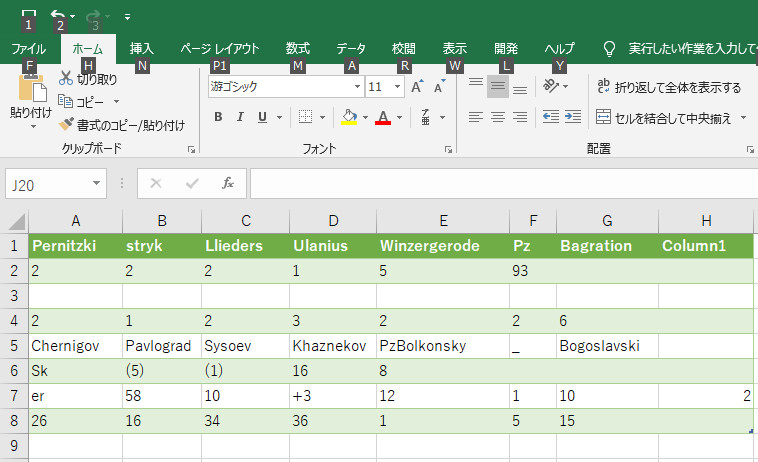
認識結果をcsvで出力し(数字に限定しない全て)、EXCELで開いた結果は、下図の通り。
一部に誤認識(3を93,27をerなど)があるが、文字を含めて認識できている。
しかし、空白をデータの区切り指定している為に、ユニット名と対応するデータがバラバラになる。
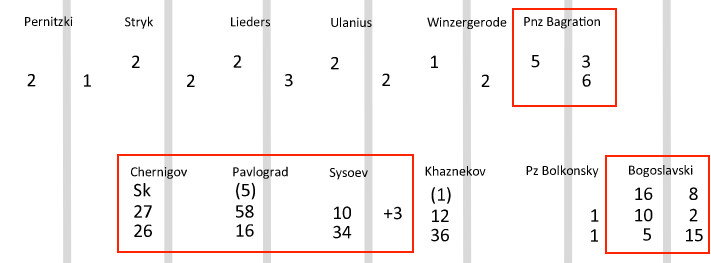
下図の赤枠で代表されるように、歩兵以外のユニットは編集に注意が必要である。
指揮官(Pnz Bagration): データ欄の1段目は空白、2,3段目でも空白の場合がある。
重騎兵=竜騎兵(Chernigov)の例: データ欄の1段目は空白かSkの場合がある。
軽騎兵=ユサール(Pavlograd)の例: データ欄の1段目は空白か(射撃値)の場合がある。
槍騎兵=コサック(Sysoev)の例: データ欄の1段目は空白で、2段めにランサーボーナスが付く(+3)。
砲兵(Bogoslavski): 1から3段目まで2つのデータ、合計6ケのデータがある。
なお、今まで数字に限定していたのには、理由がある。
それは、例えば3.(1)で数字に限定しない全てをcsvで出力すると、下図のようにエラーになる。
理由は、下図の赤線のようにcsvに出力する際に変換できない文字コードが含まれる為である。
(撮影などの劣化した画像では、認識率が低下して、変換できない文字に認識した。)

なお、エラーの解消方法が分かったので、メモしておく。
下記のWEBページにお世話になりました。ありがとうございます。
・WindowsでPython3使用時のUnicodeEncodeError(cp932,Shift-JISエンコード)の原因と回避方法
ファイルのopen時に、encoding=’utf-8’のパラメータを追加すれば、解消される。
次回へつづく
<個人的な感想>
歩兵以外では、データの有無にバラツキがあるので手動編集は不可欠である。
なかなか難しい・・・。